Linux内存管理 | 六、物理内存分配——伙伴系统 #
上一章,我们了解了物理内存的布局以及Linux内核对其的管理方式,页(page)也是物理内存的最小单元,Linux内核对物理内存的分配主要分为两种:一种是整页的分配,采用的是伙伴系统,另一种是小内存块的分配,采用的是slab技术。
下面我们先来看看什么是伙伴系统!
1、伙伴系统(Buddy System) #
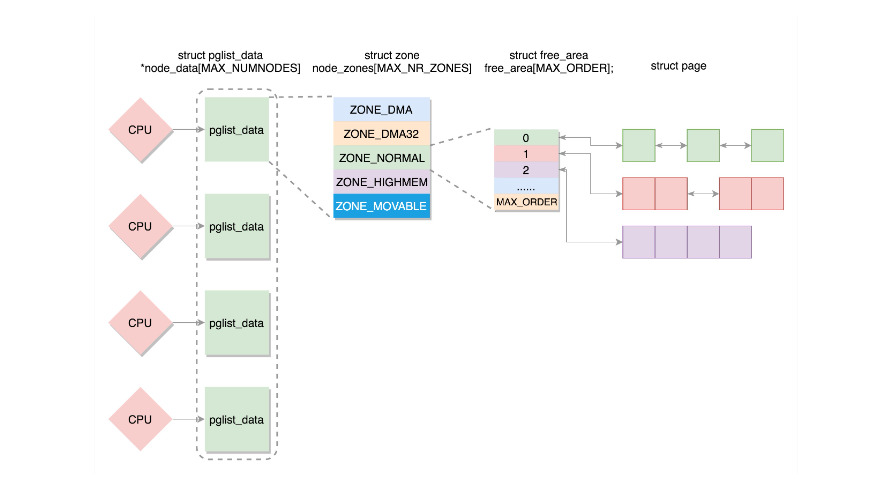
Linux系统中,对物理内存进行分配的核心是建立在页面级的伙伴系统之上。Linux内存管理的页大小为4KB,把所有的空闲页分组为11个页块链表,每个链表分别包含很多个大小的页块,有 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页的页块,最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
如下图所示:
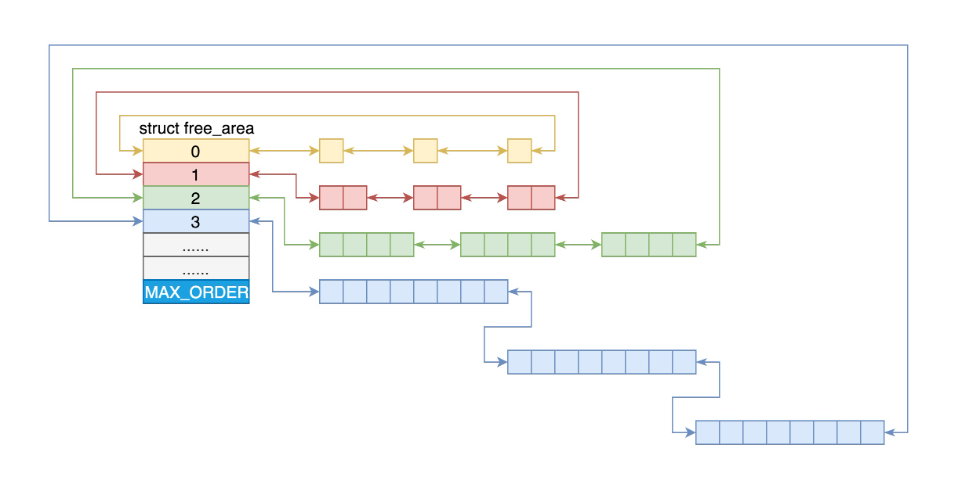
第 i 个页块链表中,页块中页的数目为 2^i。——仔细理解这个页块的含义。
在struct zone结构体中,有下面定义
struct free_area free_area[MAX_ORDER];
#define MAX_ORDER 11
free_area:存放不同大小的页块
MAX_ORDER:就是指数
当向内核请求分配 (2^(i-1),2^i] 数目的页块时,按照 2^i 页块请求处理。如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中。
举个例子:
例如,要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
上面的这套机制就是伙伴系统所做的事情,它主要负责对物理内存页面进行跟踪,记录哪些是被内核使用的页面,哪些是空闲页面。
2、页面分配器(Page Allocator) #
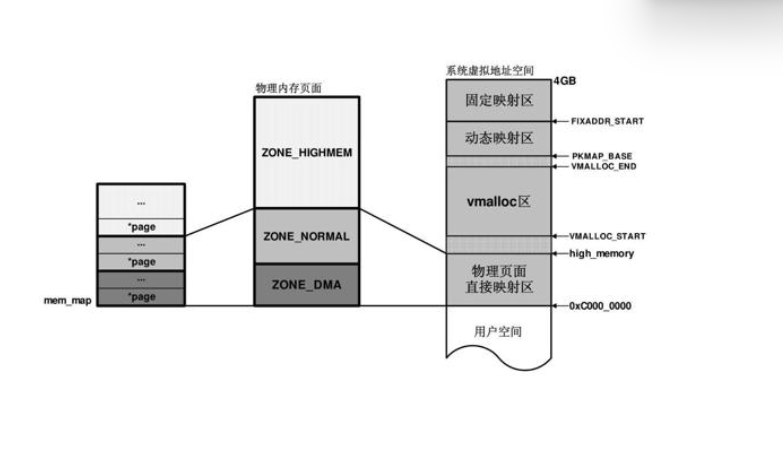
由上一章我们知道,物理内存被分为了几个区域:ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM,其中前两个区域的物理页面与虚拟地址空间是线性映射的。
页面分配器主要的工作原理如下:
- 如果页面分配器分配的物理页面在
ZONE_DMA、ZONE_NORMAL区域,那么对应的虚拟地址到物理地址映射的页目录已经建立,因为是线性映射,两者之间有一个差值PAGE_OFFSET。 - 如果页面分配器分配的物理页面在
ZONE_HIGHMEM区域,那么内核此时还没有对该页面进行映射,因此页面分配器的调用者,首先在虚拟地址空间的动态映射区或者固定映射区分配一个虚拟地址,然后映射到该物理页面上。
以上就是页面分配器的原理,对于我们只需要调用相关接口函数就可以了。
页面分配函数主要有两个:alloc_pages和__get_free_pages,而这两个函数最终也会调用到alloc_pages_node,其实现原理完全一样。
下面我们从代码层面来看页面分配器的工作原理
更多干货可见:高级工程师聚集地,助力大家更上一层楼!
3、gfp_mask #
我们先来了解一下gfp_mask,它并不是页面分配器函数,而只是这些页面分配函数中一个重要的参数,是个用于控制分配行为的掩码,并可以告诉内核应该到哪个zone中分配物理内存页面。
/* Plain integer GFP bitmasks. Do not use this directly. */
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_WRITE 0x100u
#define ___GFP_NOWARN 0x200u
#define ___GFP_RETRY_MAYFAIL 0x400u
#define ___GFP_NOFAIL 0x800u
#define ___GFP_NORETRY 0x1000u
#define ___GFP_MEMALLOC 0x2000u
#define ___GFP_COMP 0x4000u
#define ___GFP_ZERO 0x8000u
#define ___GFP_NOMEMALLOC 0x10000u
#define ___GFP_HARDWALL 0x20000u
#define ___GFP_THISNODE 0x40000u
#define ___GFP_ATOMIC 0x80000u
#define ___GFP_ACCOUNT 0x100000u
#define ___GFP_DIRECT_RECLAIM 0x200000u
#define ___GFP_KSWAPD_RECLAIM 0x400000u
#ifdef CONFIG_LOCKDEP
#define ___GFP_NOLOCKDEP 0x800000u
#else
#define ___GFP_NOLOCKDEP 0
#endif
___GFP_DMA:在ZONE_DMA标识的内存区域中查找空闲页。___GFP_HIGHMEM:在ZONE_HIGHMEM标识的内存区域中查找空闲页。___GFP_MOVABLE:内核将分配的物理页标记为可移动的。___GFP_HIGH:内核允许使用紧急分配链表中的保留内存页。该请求必须以原子方式完成,意味着请求过程不允许被中断。___GFP_IO:内核在查找空闲页的过程中可以进行I/O操作,如此内核可以将换出的页写到硬盘。___GFP_FS:查找空闲页的过程中允许执行文件系统相关操作。___GFP_ZERO:用0填充成功分配出来的物理页。
通常意义上,这些以“__”打头的GFP掩码只限于在内存管理组件内部的代码使用,对于提供给外部的接口,比如驱动程序中所使用的页面分配函数,gfp_mask掩码以“GFP_”的形式出现,而这些掩码基本上就是上面提到的掩码的组合。
例如内核为外部模块提供的最常使用的几个掩码如下:
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
GFP_ATOMIC:内核模块中最常使用的掩码之一,用于原子分配。此掩码告诉页面分配器,在分配内存页时,绝对不能中断当前进程或者把当前进程移出调度器。GFP_KERNEL:内核模块中最常使用的掩码之一,带有该掩码的内存分配可能导致当前进程进入睡眠状态。GFP_USER:用于为用户空间分配内存页,可能引起进程的休眠。GFP_NOIO:在分配过程中禁止I/O操作GFP_NOFS:禁止文件系统相关的函数调用GFP_DMA:限制页面分配器只能在ZONE_DMA域中分配空闲物理页面,用于分配适用于DMA缓冲区的内存。
通过gfp_mask掩码,更加方便我们控制页面分配器到哪个区域去分配物理内存,分配内存的优先级如下:
- 指定
__GFP_HIGHMEM:先在ZONE_HIGHMEM域中查找空闲页,如果无法满足当前分配,页分配器将回退到ZONE_NORMAL域中继续查找,如果依然无法满足当前分配,分配器将回退到ZONE_DMA域,或者成功或者失败。 - 指定
__GFP_DMA:只能在ZONE_DMA中分配物理页面,如果无法满足,则分配失败。 - 没有
__GFP_NORMAL这样的掩码,但是前面已经提到,如果gfp_mask中没有明确指定__GFP_HIGHMEM或者是__GFP_DMA,默认就相当于__GFP_NORMAL,优先在ZONE_NORMAL域中分配,其次是ZONE_DMA域。
4、alloc_pages #
alloc_pages函数负责分配2^order个连续的物理页面并返回起始页的struct page实例。
alloc_pages的实现源码如下:
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
/**
* alloc_pages_current - Allocate pages.
*
* @gfp:
* %GFP_USER user allocation,
* %GFP_KERNEL kernel allocation,
* %GFP_HIGHMEM highmem allocation,
* %GFP_FS don't call back into a file system.
* %GFP_ATOMIC don't sleep.
* @order: Power of two of allocation size in pages. 0 is a single page.
*
* Allocate a page from the kernel page pool. When not in
* interrupt context and apply the current process NUMA policy.
* Returns NULL when no page can be allocated.
*/
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
EXPORT_SYMBOL(alloc_pages_current);
alloc_pages调用alloc_pages_current,其中
gfp参数:即上文的gfp_mask,表明我们想要在哪个物理内存区域进行内存分配order参数:表示分配 2 的order次方个页。
__alloc_pages_nodemask为伙伴系统的核心实现,它会调用 get_page_from_freelist。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
......
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask) {
struct page *page;
......
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
......
}
这里面的逻辑也很容易理解,就是在一个循环中先看当前节点的 zone。如果找不到空闲页,则再看备用节点的 zone。
每一个 zone,都有伙伴系统维护的各种大小的队列,就像上面伙伴系统原理里讲的那样。
这里调用 rmqueue 就很好理解了,就是找到合适大小的那个队列,把页面取下来。
伙伴系统的实现代码,感兴趣的可以深入探究。
在调用这个函数的时候,有几种情况:
- 如果
gfp_mask中没有指定__GFP_HIGHMEM,那么分配的物理页面必然来自ZONE_NORMAL或者ZONE_DMA,由于这两个区域内核在初始化的时候就已经建立了映射关系,所以内核很容易就能找到对应的虚拟地址KVA(Kernel Virtual Address) - 如果
gfp_mask中指定了__GFP_HIGHMEM,那么页分配器将优先在ZONE_HIGHMEM域中分配物理页,但也不排除因为ZONE_HIGHMEM没有足够的空闲页导致页面来自ZONE_NORMAL与ZONE_DMA域的可能性。对于新分配出的高端物理页面,由于内核尚未在页表中为之建立映射关系,所以此时需要:- 在内核的动态映射区分配一个
KVA - 通过操作页表,将第一步中的
KVA映射到该物理页面上,通过kmap实现
- 在内核的动态映射区分配一个
5、__get_free_pages #
__get_free_pages该函数负责分配2^ordev个连续的物理页面,返回起始页面所在内核线性地址。
函数的实现如下:
/*
* Common helper functions. Never use with __GFP_HIGHMEM because the returned
* address cannot represent highmem pages. Use alloc_pages and then kmap if
* you need to access high mem.
*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
我们可以看到,函数内部调用了alloc_pages函数,并且不能从__GFP_HIGHMEM高端内存分配物理页,最后通过page_address来返回页面的起始页面的内核线性地址。
6、get_zeroed_page #
get_zeroed_page用于分配一个物理页同时将页面对应的内容填充为0,函数返回页面所在的内核线性地址。
可以看下内核代码:
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
EXPORT_SYMBOL(get_zeroed_page);
仅仅是在__get_free_pages基础上,使用了 __GFP_ZERO标志,来初始化分配页面的初始内容。
7、总结 #
以上,就是建立在伙伴系统之上的页面级分配器,常用的函数有:alloc_pages、__get_free_pages、get_zeroed_page、__get_dma_pages等,其底层实现都是一样的,只是gfp_mask不同。
