【深入理解Linux内核锁】四、自旋锁 #

上两节主要讲解了中断屏蔽和原子操作,这两个作为最底层的操作,几乎在
Linux内核中都不单独使用,下面我们来带大家了解一下常用的自旋锁!
1、什么是自旋锁? #
自旋锁是一种典型的对临界资源进行互斥访问的手段。
它的底层实现逻辑是:原子变量+判断检测。
原子变量我们可以理解为一把锁,通过操作原子变量(锁)的状态,并对其进行判断,如果锁未被锁定,我们就继续往下执行;如果锁已经被锁定,我们就原地自旋,直到等到锁被打开。
在ARM平台下,自旋锁的实现使用了ldrex、strex、以及内存屏障指令dmb、dsb、wfe、sev等。
2、自旋锁思想 #
- 自旋锁主要针对于
SMP或者单CPU但内核可抢占的情况,对于单CPU内核不可抢占的情况时,自旋锁退化为空操作。 - 自旋锁实际为忙等锁,当锁不可用时,
CPU一直处于等待状态,直到该锁被释放。 - 自旋锁可能会导致内核死锁,当递归使用自旋锁时,则将该
CPU锁死。 - 在多核
SMP的情况下,任何一个核拿到了自旋锁,该核上的抢占调度也暂时禁止了,但是没有禁止另外一个核的抢占调度。 - 在自旋锁锁定期间,不能调用引起进程调度的函数,如
copy_from_user()、copy_to_user()、kmalloc()和msleep(),否则会导致内核崩溃
3、自旋锁的定义及实现 #
3.1 API接口 #
// 定义自旋锁
spinlock_t lock;
// 初始化自旋锁
spin_lock_init(&lock)
// 获得自旋锁
spin_lock(&lock) // 获取自旋锁,如果立即获得锁,则直接返回,否则,自旋等待,直到锁被释放
spin_trylock(&lock) // 尝试获取自旋锁,如果立即获得锁,返回true,否则直接返回false,不原地等待
// 释放自旋锁
spin_unlock(&lock)
自旋锁保证了不受其他CPU或者单CPU内的抢占进程的干扰,但是对于临界区代码,仍然有可能会受到中断和底半部的影响。
为了解决这种问题,我们就要使用自旋锁的衍生。
spin_lock_irq() = spin_lock() + local_irq_disable() // 获取自旋锁并关中断
spin_unlock_irq() = spin_unlock() + local_irq_enable() // 释放自旋锁并开中断
spin_lock_irqsave() = spin_lock() + local_irq_save() // 获取自旋锁并关中断,保存中断状态
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()//释放自旋锁,开中断并恢复中断状态
spin_lock_bh() = spin_lock() + local_bh_disable() // 获取自旋锁并关底半部中断
spin_unlock_bh() = spin_unlock() + local_bh_enable() // 释放自旋锁并发开底半部中断
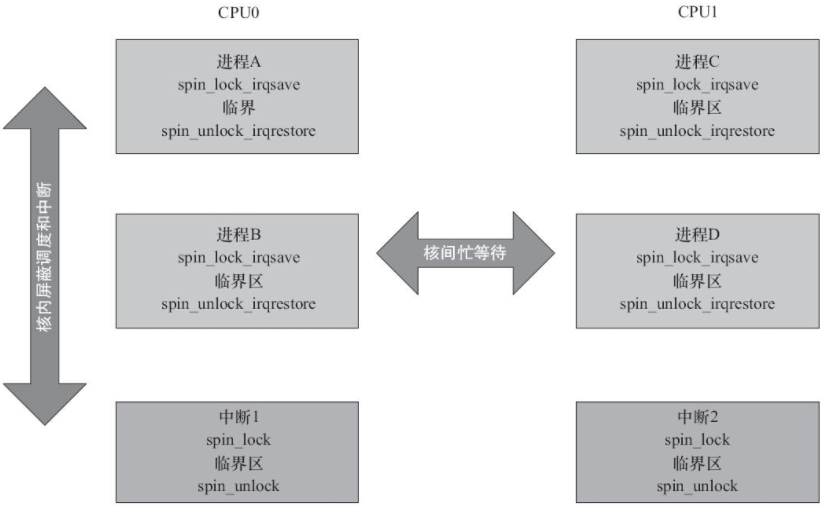
当我们的临界区代码,有可能被进程或者中断访问时,就需要在进程上下文中,调用spin_lock_irqsave()、spin_unlock_irqrestore(),在中断上下文中调用spin_lock()、spin_unlock(),如下图:
TODO:替换图片
3.2 API实现 #
3.2.1 结构体spinlock_t、raw_spinlock、arch_spinlock_t #
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u6 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
typedef struct {
union {
u32 slock;
struct __raw_tickets {
#ifdef __ARMEB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} tickets;
};
} arch_spinlock_t;
结构体名称:spinlock_t、raw_spinlock、arch_spinlock_t
文件位置:include/linux/spinlock.h、arch/arm/include/asm/spinlock_types.h
主要作用:结构体层层嵌套,用于定义一个自旋锁。
slock:32位无符号整形数据,用于锁的控制__raw_tickets:union类型,用于基于票证锁算法的自旋锁。owner:表示当前持有自旋锁的线程的索引next:表示下一个等待获取自旋锁的线程的索引
每个线程进入代码段时,会尝试获取自旋锁,如果获取失败,它们会在锁的等待队列中排队。然后,等待队列中的线程会按照优先级顺序依次抢占锁的拥有权,直到某个线程成功获取自旋锁并执行完关键代码,释放锁资源为止。
这里使用的
union联合体,其共享内存空间,其具体区别可看下面:
struct与union区别:https://blog.csdn.net/lishuo0204/article/details/118957959
3.2.2 spin_lock_init #
#define spin_lock_init(_lock) \
do { \
spinlock_check(_lock); \
raw_spin_lock_init(&(_lock)->rlock); \
} while (0)
static __always_inline raw_spinlock_t *spinlock_check(spinlock_t *lock)
{
return &lock->rlock;
}}
# define raw_spin_lock_init(lock) \
do { *(lock) = __RAW_SPIN_LOCK_UNLOCKED(lock); } while (0)
#define __RAW_SPIN_LOCK_UNLOCKED(lockname) \
(raw_spinlock_t) __RAW_SPIN_LOCK_INITIALIZER(lockname)
#define __RAW_SPIN_LOCK_INITIALIZER(lockname) \
{ \
.raw_lock = __ARCH_SPIN_LOCK_UNLOCKED, \
SPIN_DEBUG_INIT(lockname) \
SPIN_DEP_MAP_INIT(lockname) }
#define __ARCH_SPIN_LOCK_UNLOCKED { { 0 } }
函数名称:spin_lock_init
文件位置:include/linux/spinlock.h
主要作用:初始化自旋锁
函数调用流程:
// spin_lock_init
spin_lock_init(include/linux/spinlock.h)
|--> spinlock_check // 对锁进行检查,判断是否存在
|--> raw_spin_lock_init // 初始化锁
|--> __RAW_SPIN_LOCK_UNLOCKED(include/linux/spinlock_types.h)
|--> __RAW_SPIN_LOCK_INITIALIZER // 将锁初始为__ARCH_SPIN_LOCK_UNLOCKED未上锁状态
上述函数主要通过宏定义给变量.raw_lock = __ARCH_SPIN_LOCK_UNLOCKED赋值,初始化为0,即为未上锁的状态;并且提供了两个调试接口:CONFIG_DEBUG_SPINLOCK、CONFIG_DEBUG_LOCK_ALLOC,默认为关闭。
这里面有个关于spinlock_check存在的意义的讨论,感兴趣的可以看一下:https://stackoverflow.com/questions/52551594/spinlock-initialization-function
3.2.3 spin_lock #
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
#define raw_spin_lock(lock) _raw_spin_lock(lock)
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
#define preempt_disable() \
do { \
preempt_count_inc(); \
barrier(); \
} while (0)
#define LOCK_CONTENDED(_lock, try, lock) \
lock(_lock)
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
函数名称:spin_lock
文件位置:include/linux/spinlock.h
主要作用:用于在进程或线程首次尝试获取锁的时候进行自旋,不停地检查锁的状态,如果锁已经被其他进程或线程占用,则自旋等待,直到锁被释放。
函数调用流程:
// spin_lock
spin_lock(include/linux/spinlock.h)
|--> raw_spin_lock
|--> _raw_spin_lock(include/linux/spinlock_api_smp.h)
|--> __raw_spin_lock
|--> __raw_spin_lock
|--> preempt_disable
|--> preempt_count_inc
|--> barrier
|--> spin_acquire
|--> LOCK_CONTENDED
|--> do_raw_spin_lock
|--> arch_spin_lock(arch/arm/include/asm/spinlock.h)
实现流程:
preempt_disable();禁用内核抢占,确保当前 CPU 执行该代码时不会被其他进程或线程抢占。- 其通过
preempt_count_inc增加抢占计数器的值,通过抢占计数器来实现对任务的执行顺序进行管理。 - 通过内存屏障
barrier来确保前面的操作完成后再继续执行后面的代码。
- 其通过
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);通过调用spin_acquire()函数获取自旋锁,用于保护共享资源不被两个、或者多个线程所修改。spin_acquire是lockdep工具的一部分,主要用于动态检测死锁。lock->dep_map是锁的依赖地图,_RET_IP_是调用者的返回地址。这两个参数都是用于lockdep的调试信息。lockdep是一个强大的锁调试工具,它可以跟踪锁的所有获取和释放,并动态地检测可能的死锁情况。
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);实际为调用do_raw_spin_lock函数来实现获取锁并自旋的操作。
下面为arch_spin_lock汇编代码分析:
prefetchw(&lock->slock)函数用于提前加载锁的地址到处理器缓存中,从而提高锁的获取效率。ldrex %0, [%3]用于以原子方式读取锁的值到寄存器%0中,%3为锁的地址。add %1, %0, %4用于将当前获取锁的 CPU 分配的新值加上原锁值%0以及%4固定常量,结果存放在%1新值中。strex %2, %1, [%3]用于以原子方式将更新的值%1写入锁的地址所指定的内存位置,%2为写入结果。这里解释一下为什么要做
add处理:由
spinlock_t的结构体可知,是由联合体组成,并且可以通过owner和next两个字段访问,next在高16位,owner在低16位。这里上锁的操作,是将其值设置为
1 << TICKET_SHIFT,也就是高16位,即next字段设置为1,表示下一个等待获取自旋锁的线程的索引。teq %2, #0:用于测试写入结果%2是否为0,如果为0,表示锁获取成功,反之则跳转到标签1b处执行。当获取锁成功之后,程序会执行
while循环,不断等待锁的所有权被赋予当前CPU, 直到锁的所有权的拥有者持有锁为止。smp_mb()函数执行一条内存屏障,确保所有关键数据的顺序性已经刷新到内存中。
综上,spin_lock代码的作用是获取自旋锁,让当前线程获得临界资源的控制权,避免多个线程同时修改共享资源而造成数据冲突。同时,通过禁用内核抢占和使用内联函数优化的方式,保证了原子操作的执行效率和可靠性。
3.2.4 spin_unlock #
static __always_inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
#define raw_spin_unlock(lock) _raw_spin_unlock(lock)
void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, 1, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}
static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock)
{
arch_spin_unlock(&lock->raw_lock);
__release(lock);
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
smp_mb();
lock->tickets.owner++;
dsb_sev();
}
函数名称:spin_unlock
文件位置:include/linux/spinlock.h
主要作用:该宏释放自旋锁lock,它与spin_trylock或spin_lock配对使用。
函数调用流程:
// spin_unlock
spin_unlock(include/linux/spinlock.h)
|--> raw_spin_unlock
|--> _raw_spin_unlock(kernel/locking/spinlock.c)
|--> __raw_spin_unlock(include/linux/spinlock_api_smp.h)
|--> spin_release
|--> do_raw_spin_unlock
|--> arch_spin_unlock(arch/arm/include/asm/spinlock.h)
|--> preempt_enable
下面为arch_spin_unlock代码分析:
smp_mb()函数执行一条内存屏障,确保所有关键数据的顺序性已经刷新到内存中。lock->tickets.owner++:递增自旋锁的锁拥有者(Ower)计数器,这个计数器的作用是向其他任务表明自旋锁已经被释放。通过上述两个接口可知:
spin_lock:将next值加1,表示下一个等待获取自旋锁的线程spin_unlock:将owner的值加1,指向下一个获取自旋锁的线程。
dsb_sev()则用于内存同步,强制发射缓存条 (FLUSH操作),确保数据在多个核之间进行同步,以避免潜在的错误和问题。
3.2.5 spin_trylock #
static __always_inline int spin_trylock(spinlock_t *lock)
{
return raw_spin_trylock(&lock->rlock);
}
#define raw_spin_trylock(lock) __cond_lock(lock, _raw_spin_trylock(lock))
static inline int __raw_spin_trylock(raw_spinlock_t *lock)
{
preempt_disable();
if (do_raw_spin_trylock(lock)) {
spin_acquire(&lock->dep_map, 0, 1, _RET_IP_);
return 1;
}
preempt_enable();
return 0;
}
static inline int do_raw_spin_trylock(raw_spinlock_t *lock)
{
return arch_spin_trylock(&(lock)->raw_lock);
}
static inline int arch_spin_trylock(arch_spinlock_t *lock)
{
unsigned long contended, res;
u32 slock;
prefetchw(&lock->slock);
do {
__asm__ __volatile__(
" ldrex %0, [%3]\n"
" mov %2, #0\n"
" subs %1, %0, %0, ror #16\n"
" addeq %0, %0, %4\n"
" strexeq %2, %0, [%3]"
: "=&r" (slock), "=&r" (contended), "=&r" (res)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
} while (res);
if (!contended) {
smp_mb();
return 1;
} else {
return 0;
}
}
函数名称:spin_trylock
文件位置:include/linux/spinlock.h
主要作用:该宏尝试获得自旋锁lock,如果能立即获得锁,它获得锁并返回true,否则立即返回false,实际上不再“在原地打转”,也就是去掉了while循环的操作!
函数调用流程:
// spin_trylock
spin_trylock(include/linux/spinlock.h)
|--> raw_spin_trylock
|--> __raw_spin_trylock(include\linux\spinlock_api_smp.h)
|--> preempt_disable // 禁止调度
|--> do_raw_spin_trylock
|--> arch_spin_trylock(arch/arm/include/asm/spinlock.h)
|--> preempt_enable // 打开调度
下面为arch_spin_trylock汇编代码分析:
prefetchw(&lock->slock)函数用于提前加载锁的地址到处理器缓存中,从而提高锁的获取效率。ldrex %0, [%3]用于以原子方式读取锁的值到寄存器%0中,%3为锁的地址。mov %2, #0:将变量res置为0subs %1, %0, %0, ror #16:在这行代码中,%0表示slock寄存器,%1表示contended寄存器。该语句的作用是:将锁变量的值存储在slock中,然后将slock右旋16位,获得低16位的值,并将结果存储到contended中。接着将slock和slock旋转后的值相减,并将结果存储到contended中。同上,这里解释一下为什么执行
sub操作:这里的核心思想是:一个32位的值,其高16位为
next,低16位为owner,将其右旋16位后,得到的值高16位变成了owner,低16位变成了next,这时候执行相减操作,如果结果为0,则表示owner与next两个字段相等!addeq %0, %0, %4:将%0寄存器的值加上%4的值,结果存放于%0寄存器中strexeq %2, %0, [%3]:用于以原子方式将更新的值%0写入锁的地址所指定的内存位置,%2为写入结果。然后,代码会检查
contended的值。如果contended的值为0,表示进程已经成功获取了锁,函数返回1;否则,表示锁已经被其他进程持有,函数返回0。smp_mb()函数执行一条内存屏障,确保所有关键数据的顺序性已经刷新到内存中。
4、总结 #
自旋锁在我们编写内核代码时会较多涉及,其底层实现主要依赖于前面所提到的:内存屏障、中断屏蔽、原子操作!
最后,自旋锁使用的方法如下:
/* 定义一个自旋锁*/
spinlock_t lock;
spin_lock_init(&lock);
spin_lock (&lock) ; /* 获取自旋锁,保护临界区 */
. . .
/* 临界区*/
spin_unlock (&lock) ; /* 解锁 */
相信通过上面详细的拆解,到这里我们就能够对自旋锁有一个较深的认识了吧!
